Original Link: https://www.anandtech.com/show/12509/xilinx-announces-project-everest-fpga-soc-hybrid
Xilinx Announces Project Everest: The 7nm FPGA SoC Hybrid
by Ian Cutress on March 19, 2018 7:40 AM EST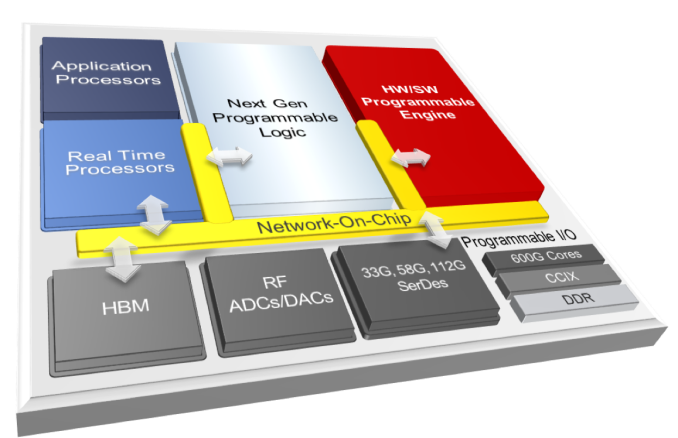
This week Xilinx is making public its latest internal project for the next era of specialized computing. The new product line, called Project Everest in the interim, is based around what Xilinx is calling an ACAP – an Adaptive Compute Acceleration Platform. The idea here is that for both compute and acceleration, particularly in the data center, the hardware has to be as agile as the software. Project Everest will combine Xilinx’s highest performing next-generation programmable logic along with application processors, real-time processors, programmable engines, RF, high-speed SerDes, programmable IO, HBM, and a custom network-on-chip. The idea is that space typically devoted to hard blocks in FPGAs (such as memory controllers) are now optimized on chip, leaving more programmable silicon for the compute and adaptability. Project Everest is one of the Three Big Trends as identified by Xilinx’s new CEO, Victor Peng.
Turn to Page 2 to see our interview of Xilinx CEO, Victor Peng
An Adaptive Compute Acceleration Platform: Project Everest
For most of the consumer market, CPUs and GPUs take up most of the processing within a system. In the data center, FPGAs are also used as a third level of compute, typically as an agile processor to assist with acceleration, and the premise is that it can be configured on the fly for an optimized compute pathway without having to spend tens of millions to create custom chips or ASICs. If an FPGA were to emulate a CPU or a GPU, it would ultimately be slower or draw more power, but typically the way CPUs and GPUs are configured are not always the best pathways for a lot of compute, and FPGAs are typically used as network accelerators or as a hub for things like semi-conductor design, emulating how other chips are built, or novel cryptographic compute workloads. If you need an FPGA with more memory for example, then the programmable logic can construct a memory controller, such that an embedded implementation with a PHY will give access to more memory. Of course, this is a simplification.
FPGAs, are by design, PCIe co-processors, much like GPUs. The workflow is somewhat similar as well after the circuit is designed: develop the code and run the data through using APIs. In recent product cycles, Xilinx has bundled new features to its FPGA line, such as hardened memory controllers supporting HBM, and embedded Arm Cortex cores for application-specific programmability. What Project Everest aims to bring to the table is another form of processing unit, combining a number of features but going beyond the current CPU/GPU/FPGA paradigm: the Adaptive Compute Acceleration Platform (or ACAP).
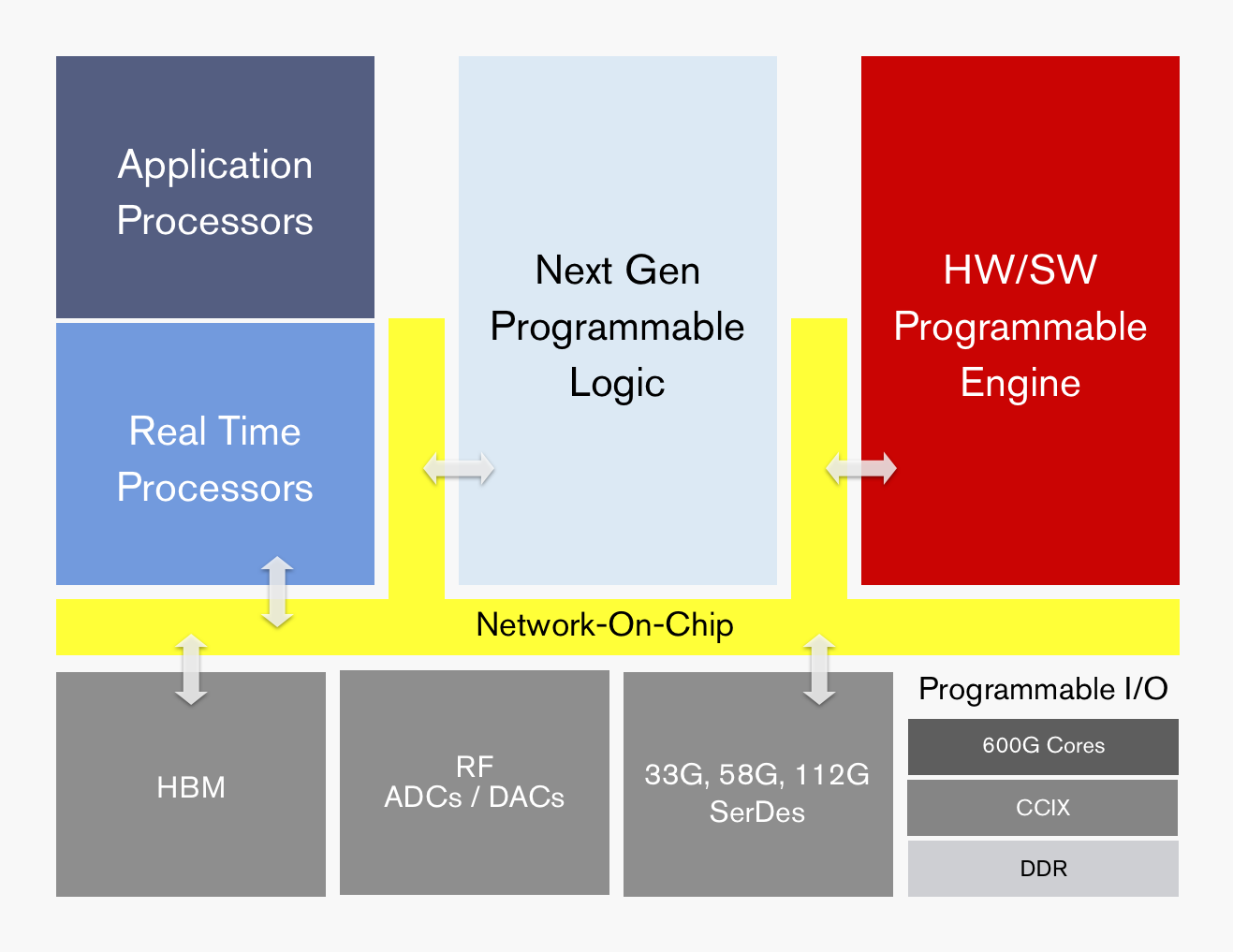
Xilinx’s ACAP portfolio will be initiated with TSMC’s 7nm manufacturing process, with the first tapeouts due in late 2018. Xilinx states that Project Everest has been a monumental internal effort, taking 4-5 years and 1500 engineers already, with over $1b in R&D costs. The final big chips are expected to weigh in at 50 billion transistors, with a mix of monolithic and interposer designs based on configurations.
Today’s announcement is more of a teaser than anything else – the diagram above is about the limit to which that Xilinx will talk about features and the product portfolio. The value of the ACAP, according to Xilinx, will be its feature set and millisecond-level configurability. For a server on the edge, for example, an ACAP can use both the programmable logic elements for millisecond bitstream reconfiguration of different processes along with the application processors for general logic or the programmable engines as ASIC-level acceleration. This can lead to, among other things, different AI acceleration techniques and 5G RF manageability by multiple containers/VMs on a single ACAP. The overriding idea is that the ACAP can apply dynamic optimization for workloads, with Xilinx citing a 10-100x speedup over CPUs and more use cases than GPUs or ASICs as a fundamental value to the new hardware, built through software and hardware programmability. Xilinx also stated that the RF will have four times the bandwidth of current 16nm radios, leveraging 16x16 800 MHz radios.
Xilinx did mention two specific features that will be coming to Project Everest. The chips will have ASIC-level blocks for CCIX connectivity – a cache coherent interconnect that promises to be the ‘one bus to rule them all’ (quote from Charlie at SemiAccurate), although Xilinx does not go into direct detail about the bandwidth. Xilinx does however mention its SerDes capability, going up to 112G PAM-4, which Xilinx demonstrated only this week at an Optical Fiber Conference. Xilinx did not state whether Project Everest will use integrated or external transceivers, however, and we will have to wait for a bigger announcement later in the year.

The ultimate goal, according to Xilinx, is for the ACAP to be a universal accelerator. The six areas that Xilinx provided as examples were for live streaming, sensor analytics, AI speech services, social video screening, financial modelling, and personalized medicine: the idea is that the ACAP can tackle all of these on the fly as a result of its feature set, hardware and software programmability, embedded connectivity, and onboard accelerators.
Xilinx is still formulating a brand name for its Project Everest products, and as mentioned above, there is expected to be a range of monolithic and interposer enabled options. Tapeout is expected in 2018, with products in 2019, using TSMC’s 7nm. This means that the first products are likely to be the high-performance, high-margin numbers. Xilinx has no direct plans at this time to bring the ACAP strategy back to 16nm or larger. Key strategic customers are already engaging Xilinx on the project.
Xilinx Tackling the Software Problem
If my employer told me to go take a week, do a course and learn a new skill, it would be to learn how to use FPGAs. I was never exposed to them much during my academic career, especially when GPUs were only just coming through as the compute platform of choice for parallelizable code. Since FPGAs and FPGA-like devices hit the market, one thing has been clear – the user has to be more of a hardware engineer than a software engineer to get to grips with them. Xilinx has seen this as a sizable barrier for entry for its product line, and part of the revised methodology under new CEO Victor Peng is to enable a new wave of users by reducing this barrier.

One of the topics in our briefing discussed alongside Everest was how to drive that new generation. The goal, according to Xilinx, is to get developers used to the FPGA as ‘just another PCIe co-processor, like a GPU’, and enable it to be programmed as such. As a result, Xilinx is pursuing a strategy of accelerated libraries, much like what has happened in the GPU space. The ultimate goal is that a developer can take a library, which has the necessary resources to configure a bit-stream on the fly and implement it to the hardware at hand, and just use it – all the FPGA reconfiguration happens at a level below what the software developer needs. So far Xilinx has been working on accelerating AI frameworks, codecs, machine learning, and database analytics, in this way. Developers still have to target the SDAccel and SDSoC software development environments, but it was clear that enabling this higher level of users is in Xilinx’s portfolio for the future, especially when an ACAP can be hardware and software configurable.
Xilinx 2018: The Focus
The briefing we had on Project Everest, because it still is early for the product line, was ultimately a chance for the company to introduce the new CEO. Bundled with this were a reformation of Xilinx’s priorities within the presentation and discussions. We have an interview with Victor Peng on the next page, but it is worth at least enumerating how Xilinx is set to approach its future.
Xilinx’s key headline that it is focusing on being a ‘Data Center First’ company. We were told that the company is now focused on the data center as its largest growth potential, as compared to its regular customer base, the time to revenue is rapid, the time to upgrade (for an FPGA company) is rapid, and it enables a fast evolution of customer requirements and product portfolio. Peng stated that Xilinx is a company that can approach compute, storage, and networking, and have a product for all three. Part of the key to being a major data center player will be the software, as discussed in the section above, but also connections with technology such as CCIX, and enablement through service providers with ‘FPGA as a Service (FaaS)’ in cloud infrastructures. Xilinx cites enterprise customers already deployed and using their hardware to afford a 40x inference speedup, a 90x analytics speedup, and a 100x genomics speedup. Use cases include personalized medicine (genomics analysis in 20 minutes, not 24 hours), computational storage, and Smart NICs for NFV.
The second element to Xilinx’s focus was to ‘Accelerate Growth in Core Markets’. So for everything that isn’t data center, and core to Xilinx’s historic and future business, the idea is to get more. We were told that these markets, such as automotive, broadcast, aerospace, infrastructure, and industrial, were looking towards embedded platforms rather than custom solutions to fit their goals. This is apparently a change from the previous generation of implementations, spurred by the availability, cost, and power, of compute. A number of these markets also rely on software defined implementations, requiring the hardware underneath to be adaptable and configurable in a transparent way.
The third element to the strategy is Adaptive Computing. The future of this strand lies in development of things like the ACAP and Project Everest, as well as deployments of current generation products, such as the Virtex UltraScale+ units with HBM announced a while back.
On the next page we had a chance to discuss Xilinx with the new CEO.
Interview with Victor Peng, CEO of Xilinx
Despite only being the job for a little over a month, Mr. Peng is well positioned at the helm of Xilinx’s future. He has been at the company for over ten years, having previously been COO (managing Global Sales, Product and Vertical Marketing, Product Development and Global Operations) and EVP/GM of Products. His background is in engineering, holding four US patents and a Masters’ from Cornell, completing the trifecta of research, sales, and marketing that typically a CEO requires in their toolset. Prior to Xilinx, Mr. Peng was Corporate VP of the Graphics Products Group for silicon engineering at AMD, as well as having spent time at MIPS and SGI.

Ian Cutress: Congratulations on the CEO position! What has it been like for the first month? Have you had to hit the ground running?
Victor Peng: Oh thank you, I appreciate it! It has been pretty busy, but it is as expected I suppose. It is very exciting! It is busy for a few reasons, as this is our 4th quarter, so we are not only getting ready to finish the fiscal year, but also we are planning all the budgeting (laughs). It is just a busy quarter in general. We have a new Sales VP who just started yesterday, so I've actually been running sales and I've been wearing two hats so it's been pretty busy. Starting to talk about the new vision and strategy is also part of the journey, but it is all good.
IC: Is the new strategy an opportunity to put your stamp on the role?
VP: It is, but I don't think of it that way. I have this steward model of the leadership – Moshi [Gavrielov, former CEO] took the company to a great place and we have this great foundation that we've built up and all these strengths that we have. You know obviously I was a part of that too in terms of when I was on the product side, but I just think that this is the right time, both from the kind of the things that we've built up internally in terms of products and technology, but also from the industry perspective like we discussed, the nature of the workloads that are going to be driving computing from the end to end. It is fundamentally different than what it was a few years ago, for example, somebody asked the question could you have done an ACAP prior to 7nm. Well we could, it would be in certain respects maybe a little less powerful, more costly perhaps, but the kind of the coming together of all those things together at 7nm makes this just the right time for the company to take this more quantum leap. It's not about legacy, but of course it also remains to be seen how long I will be CEO!
IC: The march into the data center is a story that a number of companies have been saying over the past few years. So the topic of the day is obviously the new hardware that is still a year away - what makes now the right time to discuss the ACAP and the approach into the data center?
VP: From a compute perspective we are already in the data center - Amazon today deploys our 16nm products, and some others even deploy 20nm, but most of it for now is 16nm and I think 16nm will certainly continue for the next couple of years as we bring in our 7nm product. The last year was the first year we really made very significant progress in the data center, not only because that was the year that FaaS [FPGA as a Service] got announced and deployed, but because of other engagements that we have such as storage as well as in networking. I think the number of businesses that we are engaged with all the hyperscalers as well as some OEMs. The models that people are doing are not only FPGA servers, but also just internal private acceleration.
I think you know we started before 7nm and I think that's a good thing because if we were starting just at 7nm and people didn't even have the familiarity with us then why they would use our platform to begin with? We would have an even bigger hurdle but I think that now that 16nm will get the mindset out there, it will hopefully give people a little bit of understanding as to what we offer and why it has value.
7nm ups the level of our platform significantly, and I think during the 7nm time frame is certainly I think we will have growth and a reflection of our product portfolio.
IC: Is there no desire to use half nodes like 10nm?
VP: We didn't do that for a variety of reasons. For one, if I just looked at our product cadence and when 10nm would come out, it was not a good lineup. But the other thing is that the delta between 10nm and 16nm, compared to 7nm and 16nm, is much less significant. Let’s face it, as you follow a lot of tech, it is really the handsets that need this almost annual thing. Because Moore's Law is no longer on track, everybody is coming out with variants to their process: plus, plus plus, and this-that –and-the-other-thing. This is largely because the handset guys, and every year they have to come out with something because every year there is a Christmas holiday and a consumer business.
So for not only us, but other kinds of more high-end computing applications, they don't refresh every year so we've just picked the right technology so.
IC: For the ACAP, it feels as if Xilinx is moving some way between a FPGA and an ASIC, having hardened controllers on silicon and implementing more DSPs and application processors. Is that a challenge to your customers that are currently purely FPGA based?
VP: Well I first want to challenge that a little bit. I think in a sense you are looking at an implementation perspective, and if you are saying that there are blocks that are implemented with ASIC flow, that is true. But even the things that we are implementing with ASIC flow, we are still maintaining some level of hardware programmability. At the end of the day, we are going to play to our strengths, right? Our strength is our understanding in how to enable people to use the power of hardware programmability. We crossed the chasm of being only hardware programmable to being software and hardware programmable.
It's a little bit hard to talk the new product without pre-announcing some of the features, but I talked about hardware software programmable engine, which won't be an engine that is customizable down to a single bit, but it will have notions of some granular data paths and memory and things like that, and it has some overlay of an instruction set, but while most people won't program it, it still has hardware programmability. We’re not just somebody else coming out with a VLI doping multi core architecture because then what is the difference between us and someone else right? There's always going to be that secret sauce.
Also, there's no value for us in creating a custom CPU, like an Arm SoC - not for the applications we want. If we were doing a server class processor you would need to take an Arm architecture license and create your own micro-architecture, but there's no value in us doing that, but we have embedded application cores in our ACAP. So, some of the things are implemented from an ASIC flow and is just like a hard ASIC as any other one. But also I'm not going to create a GPU architecture either - some of our products have a GPU in it, a very low GPU more for 2D kind of interfaces and stuff like that.
But when there is heavy lifting, like acceleration, there I will always try to find a way where we could add value in terms of the programmability. For the challenge of the programmability to the customer, we have already crossed that chasm once with Zynq, so it doesn’t need be a hardware expert anymore to use these. There is a software team working with that and now with FDSoC and some of these design environments you don't absolutely need the hardware design anymore because there's just many more systems and software developers than there are FPGA designers, right?
IC: One of the things that came out today with was your discussion on how implementing libraries and APIs to essentially have the equivalent of CUDA stack for the Xilinx product line. Training people on that sort of level of API is something that NVIDIA has done for the last 8 years. Is that the sort of training program that is appealing to help improve the exposure of these types of products?
VP: I'm not the one to get into the details, but I actually have people on my team that feel like we're even easier to use than CUDA! But I what I would say is in general we are going to try enable more innovators, and if the innovators are used to things like the TensorFlow Framework, we'll do that. You know we have even enabled python, right? Because of younger programmers it is probably more relevant to do python than have to do something like C or C++ or something that. But in other areas people still develop to those other languages, so you know it is really all about us trying to enable more innovators with the framework and development experience they are used to – we are going to try match those as much as possible
At some level there isn't going to be a compile step, which isn't going to be like software. Because it is physics, we are actually not going to have to do something but it doesn't mean that they always have to do it. As you can imagine when you are in a development cycle you could do very quick compiles and then work out when you're doing. Here's the production thing though - you could take longer with a new platform, but we're trying to minimize that. The general mantra is to try and make the experience like any other software target or platform, but getting a custom hardware engine underneath the hood and they don't have to really muck with it.
IC: I mean with something like the APAC it is clear that cloud providers would other this as a service, as they want a multi-configurable system for their users. But beyond the cloud providers, are people actually going to end up deploying it in their own custom solutions -with this amount of re-configurability, do you actually see them using it in a ‘reconfigurable way’ rather than just something that's fixed and deployed?
VP: That's a good point - I think that it wouldn't be necessarily that everybody dynamically configures it when it is deployed, but we do see that and I'll give you an example as far away from the cloud as you could imagine. There are a lot of people in testing instruments. Now some test instruments are kind of like a reconfigurable panel, with people moving the panels that have hard knobs, so if you can virtualize the interface when they select things, they can just reconfigure it to do a different thing with some of the guts of the electronics - for example, a situation where eight analogue testing components are being rotated. Like anything else, they try to move to digital as soon as possible, so the ability to completely reconfigure something is vital.
IC: Would you consider that a mass scale deployment, rather than prototyping?
VP: No it's not prototyping – it is a tester, but somebody using it on the bench. If they want the scope to do this or that, they can change the functionality on the fly. It is deployed, right, up and down in many engineering workshops.
That's a good example, especially if we look at telecommunications. 5G is not really a unified global standard – it is multiple standards that vary by geography, by region, and because it's going to be around connectivity there are new band radios, as well as different form factors and different regions and even down to different large customers that demand certain things. So our traditional customers in communications still need some degree of customization. One of them said to me that last year they had to do on average 2 + radios a week, because they always need to customize something about the frequency bands or the wavelengths or something about the radio. So even if it is stuff they have already built, they always still have to have some degree of customization now. Within that deployment, there will be a customer that has to change things? I could tell you actually in aerospace and defense, there are applications for security reasons, people actually want to reconfigure dynamically when it's deployed.
So it's a range - some will reconfigure when it's deployed, some will do it when they are trying to scale their product line, but in the cloud whether it's public or private I think, clearly there will be different workloads right.
IC: The ACAP schedule is for tape out this year, with sales and revenue next year. Aiming at 7nm means you're clearly going for the high end, and previously you said 16nm would have had deficits compared to using 7nm. In time do you see this sort of type of ACAP moving down into the low end?
VP: I'll put it this way - our selection of technology is primarily based on what is the right match for the end solutions. Last year we did some new 28nm tape outs, despite the fact that we had finished our original plans at 28nm a long time ago. But for the more cost and power sensitive segments, and we're talking about $10 a blow kind of segments, you don't need 20nm or 16m, but it might be kind of hard to reach that price point too in a lot of cases. So, we will still do some of those older technologies for other products, but there are some new IP blocks that are brand new only in 7nm. It is quite costly to implement a new IP block and the technology after all. But if there is a big enough opportunity and we have important enough customers or a growth segment, we would do it.
IC: Any desire to make products like these act as hosts, rather than just attached devices or attached accelerators?
VP: Well yeah, we have the Zynq product line in the data center today, and pretty much people are using pure FPGAs in the compute side and in some other areas people are finding use for a remote processor that doesn't have to do as much heavy lifting - in fact in most cases it's doing some sort of management function. So, I’d say yes, today because it's mainly a pure accelerator and it needs a local host, but I think in the future we will see that change.
I mean basically you don't want to have to go back to that host – it is costly on multiple levels and if you have a host that can do it locally, such as the embedded Arm core, you don't want to use that expensive CPU cycle that's remote, as overall you lose performance.
IC: Back at Supercomputing we saw a research development project about just network attached accelerators, so not even with a host. You just attach it in and...
VP: Exactly, and actually that's how Microsoft has eliminated this issue – it is connected to the network and so they can talk peer to peer to others. They don't necessarily even have to go to the CPU at all, but if they do, generally it's just like a CPU process - it's more like a batch, do a big job, come back, so you don't have to have lots of communication.
IC: Obviously the biggest competitor you have in this space (Intel/Altera) has different technologies for putting multiple chips together (EMIB). Is Xilinx happy with interposers? Is there research into embedded package interconnects?
VP: I think it's all about what's the problem trying to solve. If you need massive amounts of bandwidth, the interposer, is the way to go, based on TSMCs CoWoS technology, which we call SSIT. You know InFO (TSMC’s Integrated Fan Out) is much more limited, so if you don't need huge amounts of bandwidth and you don't need to connect many chips, InFO could be interesting.
It's all about technology. I mean we're not like religious about it, and if you could do what you want with InFO or a traditional MCM then OK, but it is really all about what you're trying to do. But yeah, we are quite comfortable because generally for the problems we are trying to solve, there is a need for a lot of bandwidth and fairly low latency. We've been doing this since 28nm, so you know 16nm is like our 3rd generation and 7nm will have both monolithic chips and we'll still use interposer technology. I mean that's why we could do this chip right [holds up Virtex UltraScale+ with HBM].

IC: There's a bit of a kerfuffle with your competitors about who was the first to have HBM2, comparing announcing versus deploying.
VP: I was just going say! Even before they were part of Intel, Altera was pretty good about announcing and showing technology demonstrations, but when you look when you can actually deploy something into production that is another story. You know more recently we've actually both announced earlier and deployed earlier, but in this particular case, okay they claim that their getting out there sooner, but we'll see who gets out there in production. Because remember, EMIB has never seen production in anything yet,, so you know, this is like I said - our 3rd generation of production and high volume is very reliable for our kind of customers.
IC: With Zynq already using Arm processors, will the ACAP application processors also be Arm, or if they can have RISC-V cores, or others?
VP: We're still going with the ARM architecture. I think it is the broadest set of architecture for embedded applications and, you know in the case of the heavy-duty kind of acceleration where the host is off board, it could be anything. For the off board host, we interface with OpenCAPI, and obviously we're driving CCIX, and we are working with PCIe and at SC17 we had a demo with AMDs EPYC server together with our processor.
IC: For Project Everest, can you comment on security and virtualization?
VP: We've been working on security quite a bit. We traditionally leverage a lot of things into the more pure FPGA but with Everest, as they all have SoC capabilities, everything will be leveraged together. I think everybody knows that with the world becoming very smart and connected it means the attack surface is pretty much the entire world. Since we are in applications like automotive, they care a lot about that. The hyper-scalers care a lot about security as well, except they don't have to worry about physical tampering as much, but in the automotive we actually have to care about physical tampering as well as software attacks. So you know we do TrustZone, we have all kinds of internal boots so that people won't see memory traffic over interfaces. We have stuff for defeating DPA, we have all kinds of things. In fact, if we detect anomalies, it auto shuts down. Because we do get a lot of very secure customers, such as the aerospace and defense industries, we work with the agencies that are very sensitive to this thing.
We also get involved in safety, and it is interesting because they are not exactly the same thing - safety is about ensuring the thing doesn't harm people, and security is about people not harming the thing. But we're finding more and more applications that care about both. An example of that might be robotics, drones, etc.
One other thing about security that I think is really good about our technology - the security people really like it if you could do redundancy, but implement it different ways. Because of the diversity, if you attack one thing, it doesn't mean you can attack the other. The fact we can run things in the applications processer, the real time R5's, and in the fabric, means the level of diversity you can get and then poll to see if you get the same results is quite a bit richer than you know what fixed functions chip could do.
IC: With Everest, with things like the on-chip interconnect, is that Xilinx's IP?
VP: The NOC that is connected to all the blocks, that is our design. Internally in our SoC, we actually licensed a 3rd party NOC. But the reason we chose to the main NOC proprietary is because the requirements we needed for this adaptability a little different. If it was look like everything was an ASIC block, we could in theory use a licensed IP, but there are some unique things to do when you have these very flexible things that are being implemented in lots of different ways.
IC: So what sort of different things can you do?
VP: This is probably where I should get one of my architects! It's probably best for me to get into comparing some of these architectures from other companies - we looked at them, and as I mentioned we actually use one of them within the SoC block. But we found that we can't use it for our own and they didn’t have the tools and things that you have to give people in order to interface to that.
IC: Most of our readers are familiar with the ARM interconnects because of mobile chips, so I could assume that you'll have one of those inside the SoC block.
VP: We do, and it in fact most of our IP, even in our soft IP blocks, most of the interfaces are very AXI like. We help drive some of the design - they had heavyweight AXI for some blocks, and you really don't need that heavyweight in a sense, so we work with them on the streaming, using a more slim AXI. What I should really do is a good point that when we do announce the details of the ACAP we can compare and contrast the differences that help people because they have a reference point.
Many thanks to Victor Peng and his team for their time.
Also thanks to Gavin Bonshor for transcription.






