Original Link: https://www.anandtech.com/show/14751/hot-chips-31-live-blogs-ibms-next-generation-power
Hot Chips 31 Live Blogs: IBM's Next Generation POWER
by Dr. Ian Cutress on August 19, 2019 12:00 PM EST
12:34PM EDT - We're here at Hot Chips 31 / 2019, and the first talk to be live blogged is IBM's newest variant of its POWER CPUs.

12:37PM EDT - Quite possibly the biggest Hot Chips crowd I can remember.
12:45PM EDT - The Arm talk is set to finish here in a bit, then IBM will start
12:45PM EDT - We already covered Arm's Neoverse N1 strategy earlier in the year: https://www.anandtech.com/show/13959/arm-announces-neoverse-n1-platform
12:55PM EDT - Just finishing up the previous talk

12:57PM EDT - Hopefully this is about POWER10 :)
12:57PM EDT - It could be the Power9 IO chip
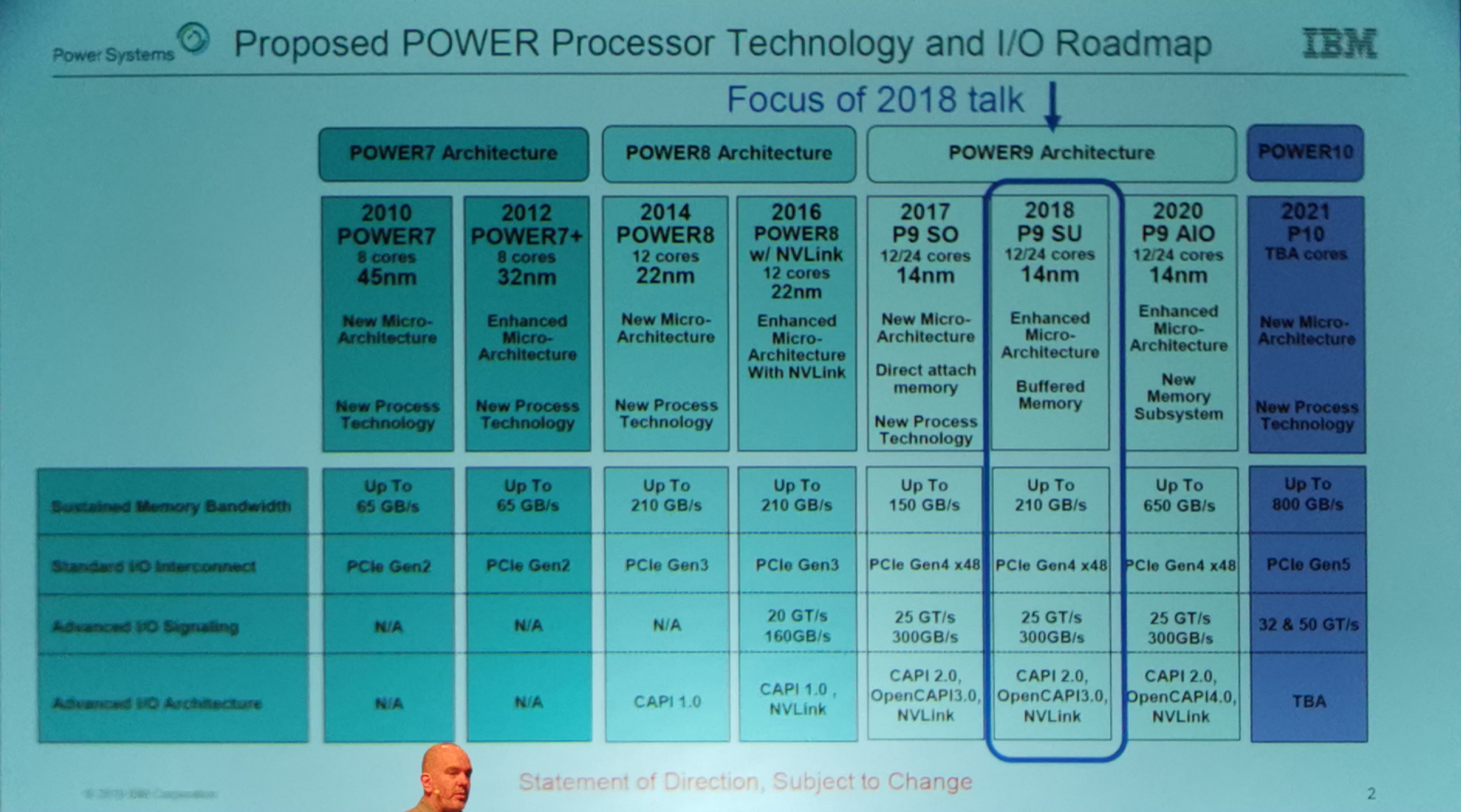
12:58PM EDT - 2018 talk was about Power9 SU core
12:58PM EDT - IBM now has family of processors. Start with some one up front, and work on the rest of the family
12:58PM EDT - Scale out first, then scale up
12:58PM EDT - One optimized for dual socket, one optimized for 16 sockets
12:59PM EDT - Power9 AIO does things they wanted to do before power 10
12:59PM EDT - new accelerator technology deployed on Power9
12:59PM EDT - Today in Power9
12:59PM EDT - Power10 for 2021
12:59PM EDT - New core on Power10 and new transistor technology in 2021
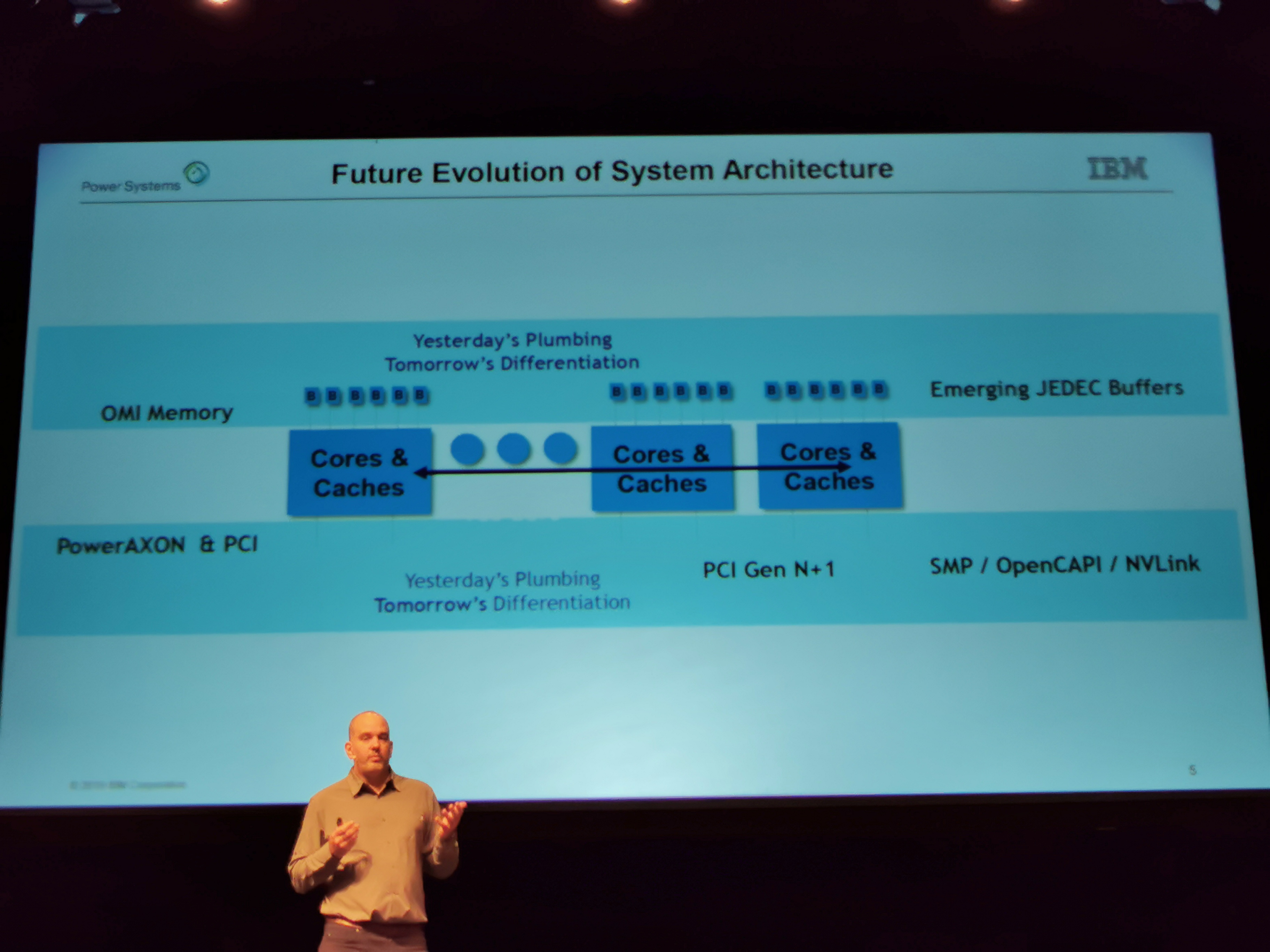
01:00PM EDT - Accessing heterogenous systems
01:00PM EDT - Need to focus on diverse acceleration devices and diverse memory devices beyond CPUs
01:01PM EDT - Need to focus on heterogenous systems, not just GHz
01:01PM EDT - Need to deploy different types of hetergeneous systems

01:01PM EDT - Trying to remove the different types of SerDes on a chip. Want to consolodate these down to a single design
01:02PM EDT - On Power9, now only have two types of SerDes. PCIe and everything else is built on 25G SerDes
01:02PM EDT - SerDes can make something area and power efficient when fixed to 25G, then just scale the number of links
01:02PM EDT - Take all the 25G signals from the chip and deploy composable systems across different accelerator technologies
01:03PM EDT - NVLINK and OpenCAPI and OMI
01:03PM EDT - OMI is the memory interface to connect memory across SerDes

01:04PM EDT - On-chip Gzip accelerator
01:04PM EDT - IBM has delivered #1 and #2 supercomputers on the list

01:04PM EDT - Built for the AI era
01:05PM EDT - Now OpenCAPI, IBM sees it as being very important in future accelerator systems

01:05PM EDT - Minimizing overhead and latency that PCIe has
01:05PM EDT - Accelerators not only GPU, but SmartNICs, networking, FPGAs, AI accel
01:06PM EDT - Want software to take data from anywhere in the system on any device
01:06PM EDT - (some of the images here look low quality - click through to see full quality)
01:06PM EDT - Power9 has direct attached memory
01:07PM EDT - Some of the former secret sauce technologies are in the new open memory standard
01:07PM EDT - Can deal with asymmetry
01:08PM EDT - Having this connectivity allows for independent development of accelerators rather than focusing on the CPU
01:09PM EDT - Don't want programmers to worry about host-to-device connectivity
01:09PM EDT - Also OpenCAPI helps with security
01:09PM EDT - Prevents an accelerator crashing a whole system
01:10PM EDT - Need to make sure accelerators can't add in potential cache coherent bugs
01:11PM EDT - Aligned all packers with deserialised interface
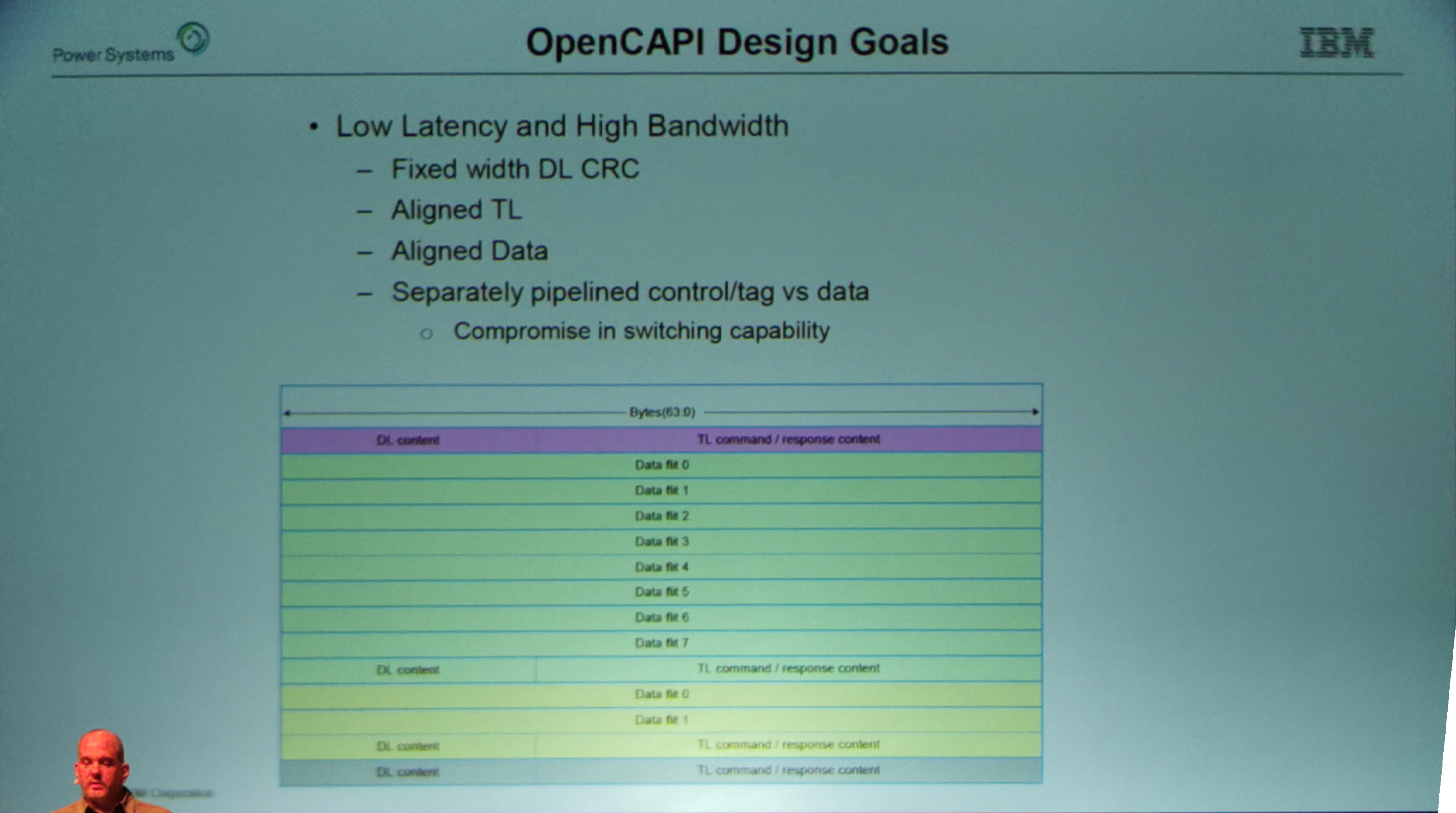
01:11PM EDT - Accelerators always see aligned data to help make assumptions for performance
01:11PM EDT - Can start processing the command before checking the CRC
01:12PM EDT - Separately pipelined control/tag vs data
01:13PM EDT - (coherence over switching is not supported in OpenCAPI due to complexity)
01:14PM EDT - 1/6th the cost in die area to put OMI instead of DDR
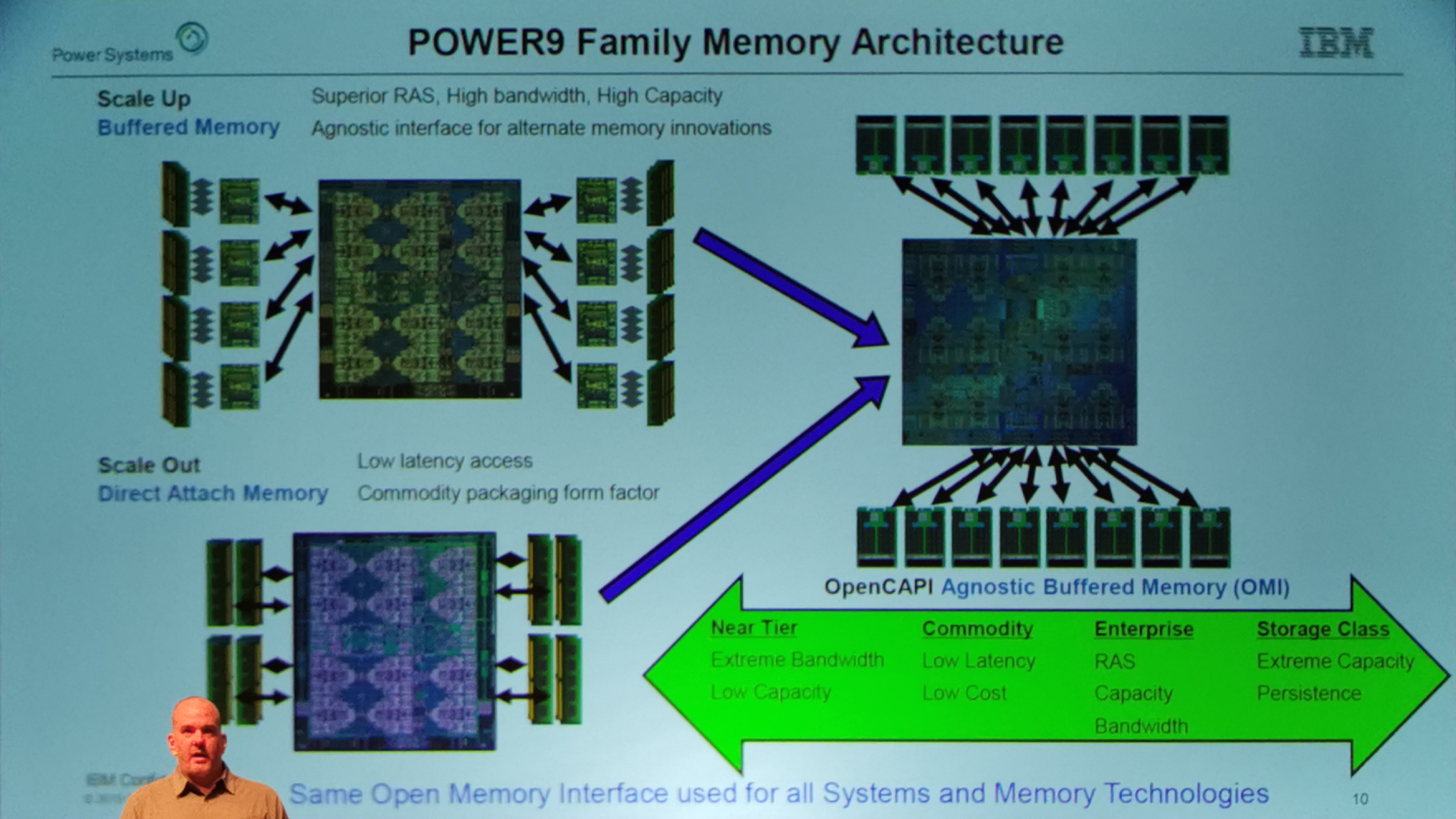
01:14PM EDT - So memory is easier to support
01:14PM EDT - Can enable more bandwidth in smaller ASICs with OMI
01:15PM EDT - Differential buffer attach is now agnostic - the buffer is on the memory
01:15PM EDT - Can put buffered DDR or GDDR, rather than one or the other
01:16PM EDT - OMI is lighter weight and open to enable more ecosystem support

01:17PM EDT - With OMI memory, based on OpenCAPI SerDes, can use multiple DDR4 and DDR5 on the same system with the same connector
01:18PM EDT - e.g. if enabled on AMD sIOD, would decouple memory technology from host silicon development
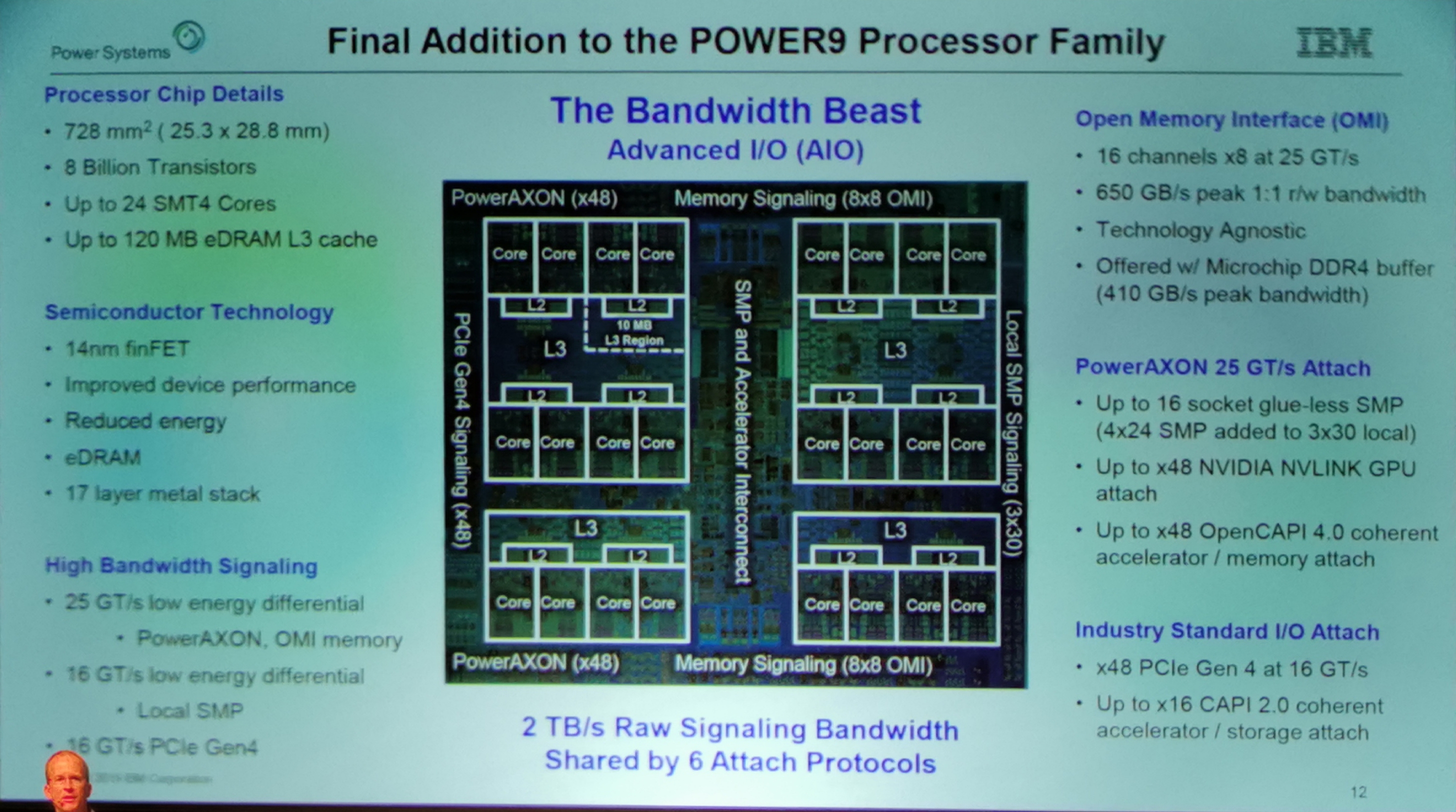
01:19PM EDT - Power9 Advanced IO chip = P9 AIO
01:19PM EDT - 728mm2, 8B transistors
01:19PM EDT - 24 SMT4 cores, 120 MB eDRAM L3
01:19PM EDT - Built on 14FF (GF?)
01:19PM EDT - 17 layer metal stack
01:19PM EDT - 16 channels of x8 OMI, 650 GB/s peak r/w bandwidth
01:20PM EDT - 48 lanes of PCIe 4.0
01:20PM EDT - Up to x16 CAPI 2.0
01:20PM EDT - Up to x48 NVLINK attach
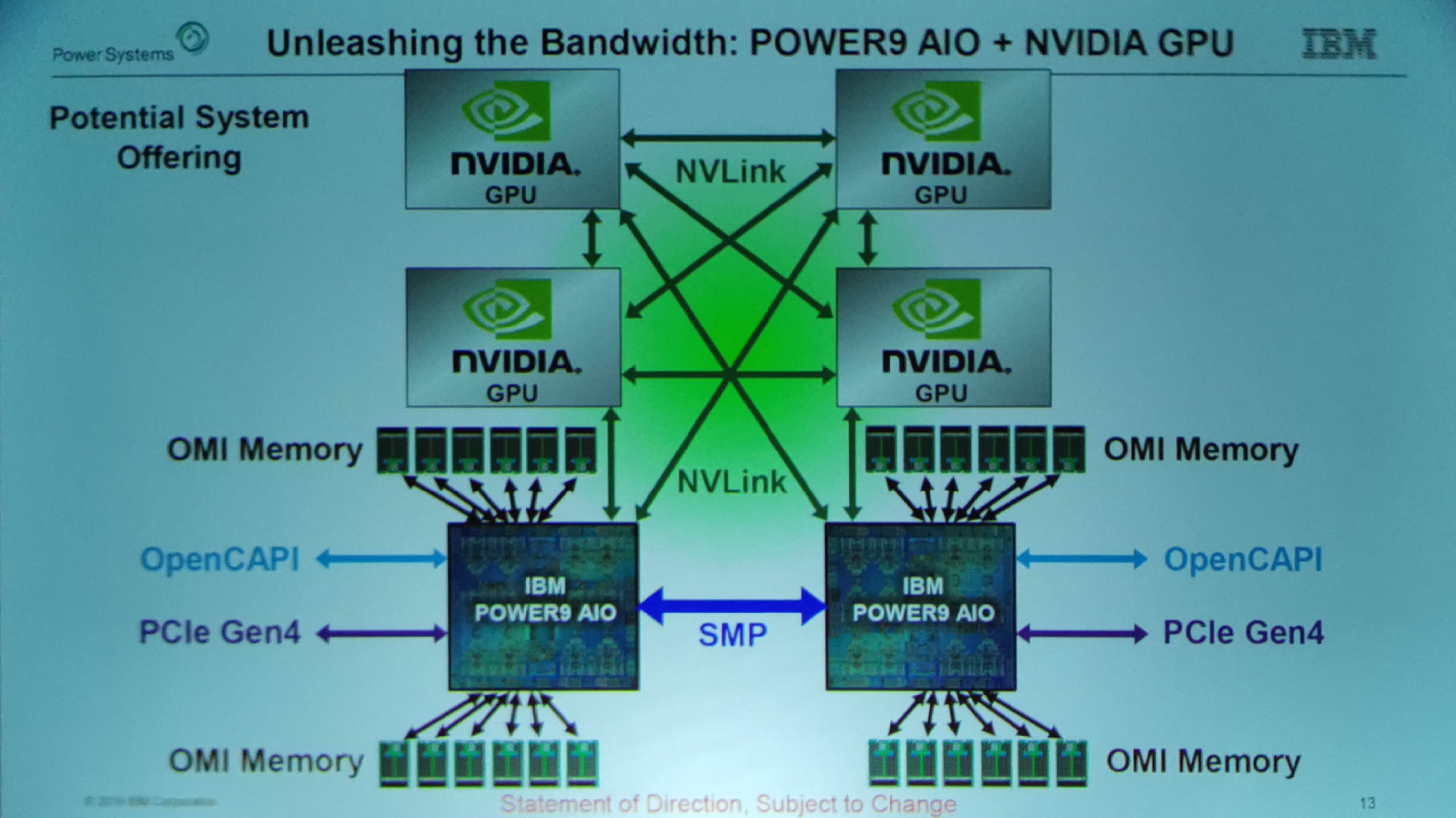
01:20PM EDT - Shows 2S replacement, but can scale to 16 socket
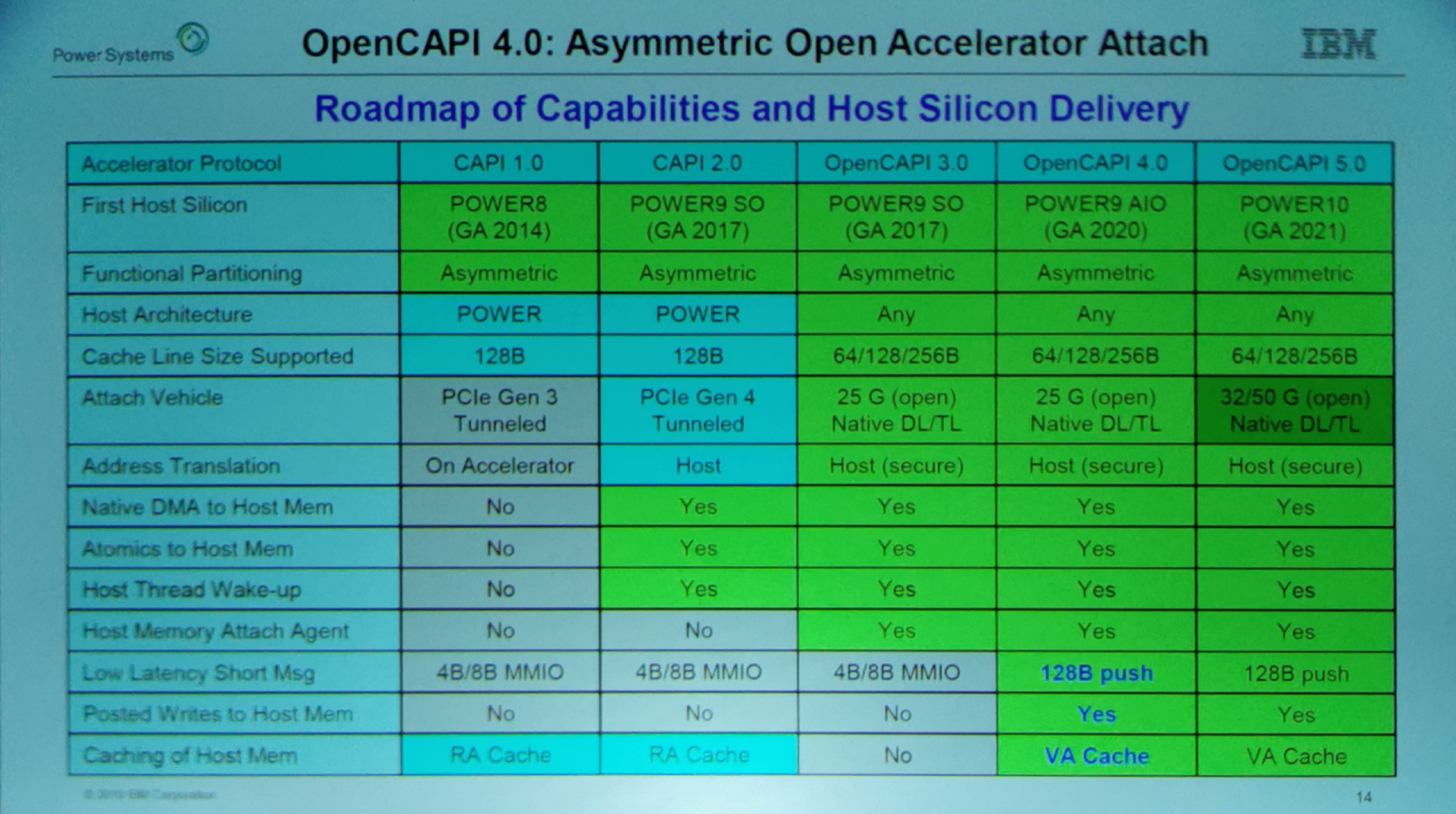
01:21PM EDT - OpenCAPI 4.0
01:21PM EDT - support for 64/128/256B cache lines
01:21PM EDT - supports 128B messages for low latency
01:22PM EDT - Supports virtual address cache for system memory
01:22PM EDT - Host manages the higher level cache coherency
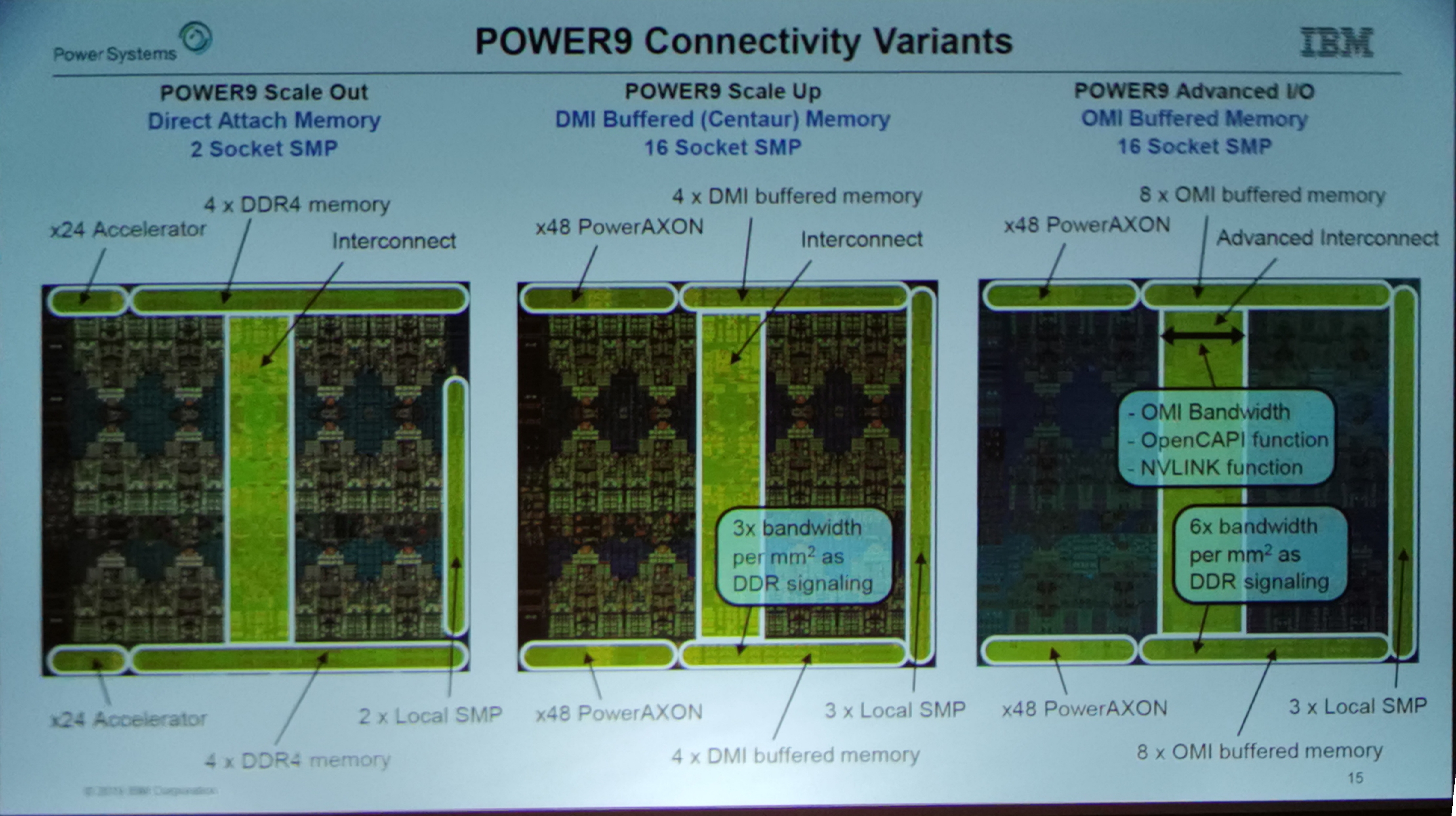
01:23PM EDT - P9 SU supports 4xDDR4, P9 SO supports 4x Centaur, P9 AIO supports 8x OMI
01:23PM EDT - On each side



01:24PM EDT - OMI DDIMM looks very different
01:24PM EDT - Will see if I can get a better photo
01:25PM EDT - Microchip SMC1000 chip used on the OMI DDIMM
01:25PM EDT - effective bandwidth and latency equivalent to LRDIMM

01:26PM EDT - Q: energy per bit on memory vs DDR?
01:27PM EDT - A: Don't have numbers here. We shifted power from the DDR PHY onto the memory DIMM which helps with cooling conditions. The 8 lane memory device can move to 2 lane or 4 lane depending on use. It does dynamically shift based on utilization. Better than DDR anywya
01:28PM EDT - Q: Does the OMI DDIMM have a cache? A: No, it's a slimmer device with write buffering no caching
01:29PM EDT - Q: Is OMI like CXL? A: Viewing CXL is focused more on accelerators. OMI is available today and ahead of the competition and been in development a long time. I'd be surprised if other buffered memory solutions get as low latency as us. I'd be surprised if CXL has such a low latency to memory
01:30PM EDT - That's it for this talk. Small break now, next talk for live blogging is MLperf






